Address
268 Bath Road
Slough, SL1 4DX
Phone
+44 (0)1753 708 529

The last few years has seen a new concept emerge in the world of data management that attempts to bring some of the best features of Data Lakes and Data Warehouses together into something new – a “Data Lakehouse”.
To understand where the concept comes from we have to understand a bit of history. Data Warehouses became the de-facto way of storing and reporting on nicely structured data from the 1990s onwards. If your source application data was already in a relational database, then it was fairly straightforward to push that data into a data warehouse and transform it into a model optimised for speedy and easy query. A fast database with a well defined data model and a whizzy BI tool was (and still is) a great way to do reporting and analysis.
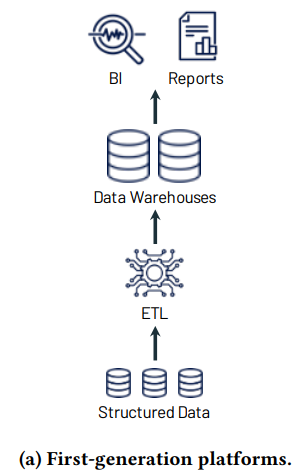
Moving on to the 2010s however and increasingly the world’s data started to change. Business applications became ever more inter-connected and APIs became key for accessing application data. That meant an explosion in the amount of data stored in semi-structured formats such as JSON. Cloud platforms and their unlimited computing power meant it was now also possible to extract useful information from vast amounts of unstructured data such as images, video, sound and raw text.
The reality was that this kind of data just didn’t fit nicely into your data warehouse and it was too expensive to even try. Plus your databases just weren’t designed to support the growing demand for machine learning workloads that required repeated large scale data scans.
Open source developments in the early 2000s such as Hadoop and Hive meant it was now a lot easier and cheaper to access and analyse data in its raw form. The theory was you could now just throw your raw data files into a big and cheap data storage platform and you had yourself a Data Lake that your analysts and data scientists could be let loose on with a plethora of new query tools.
Many people predicted the death of the data warehouse as a result, but that didn’t happen. Why?
As a result companies today are typically forced to use both technologies in a two tier architecture – data warehouses for regular BI reporting and analysis, alongside data lakes for long term data storage and ad-hoc data science and machine learning.
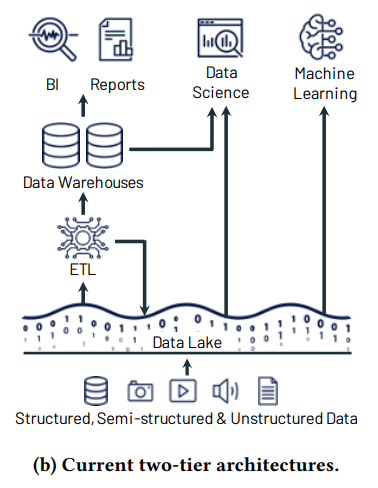
So while this does give you the best of both worlds, you now have added complexity and cost because:
The idea is to create a single data platform that combines the easy and structured querying capability of data warehouses with the flexibility, openness and cost effectiveness of data lakes. Some of its main features are below:
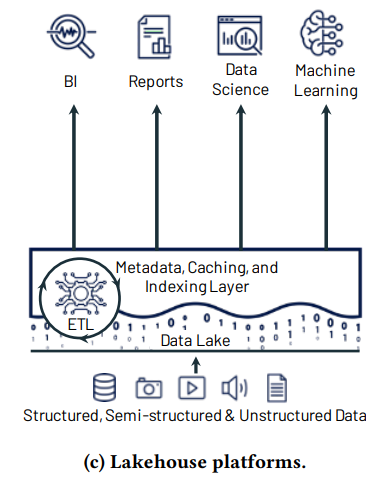
It can be summarised as follows. All your data is stored in one place, in cheap (typically cloud based) object storage, and is given structure and meaning via a metadata layer. This metadata layer enables the data lake to be queried directly by any BI tool as it effectively presents the data as SQL tables and views, and it also can act as a data governance catalogue. The layer can also be used to provide transformed (modelled) data and this can be cached and indexed for optimum query performance, but it can also be bypassed for data science and machine learning workloads that work best with raw data files.
We are starting to see growing adoption of open source lakehouse platforms such as Delta Lake and Apache Hudi plus commercial offerings from companies such as Databricks and Snowflake which are based on lakehouse architectures, and the cost vs performance metrics of these platforms looks very promising – see https://www.cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf.
Plus the major database vendors have all added lakehouse features to their products and services recently by providing the ability to query data in object storage directly (for example Azure Synapse Analytics, Google BigQuery and DataPlex plus Amazon Redshift Spectrum), indicative of its growing acceptance in the industry.
As a concept, the data lakehouse architecture certainly makes a lot of sense, providing opportunities for companies to simplify their data ecosystems, reduce costs and ultimately enable improved data analysis capability.


