Address
268 Bath Road
Slough, SL1 4DX
Phone
+44 (0)1753 708 529

In order to run some code in the cloud you would traditionally have to fire up a server specifying an upfront hardware configuration (CPUs, RAM, Disk etc), an operating system (Linux, Windows), plus a software “runtime” environment (Node, Python, Java etc). All of which requires management on your part – sizing, installing, securing, patching, maintaining and so on.
Today, cloud providers provide fully managed software environments that let you just run code without the hassle of managing those servers – hence the term “serverless”.
Serverless is rapidly becoming a key component of a company’s cloud infrastructure. Usage tripled between 2019 and 2021 so it’s one of the fastest growing cloud technologies. The chart below for example shows the growth in the number of serverless functions running on AWS:
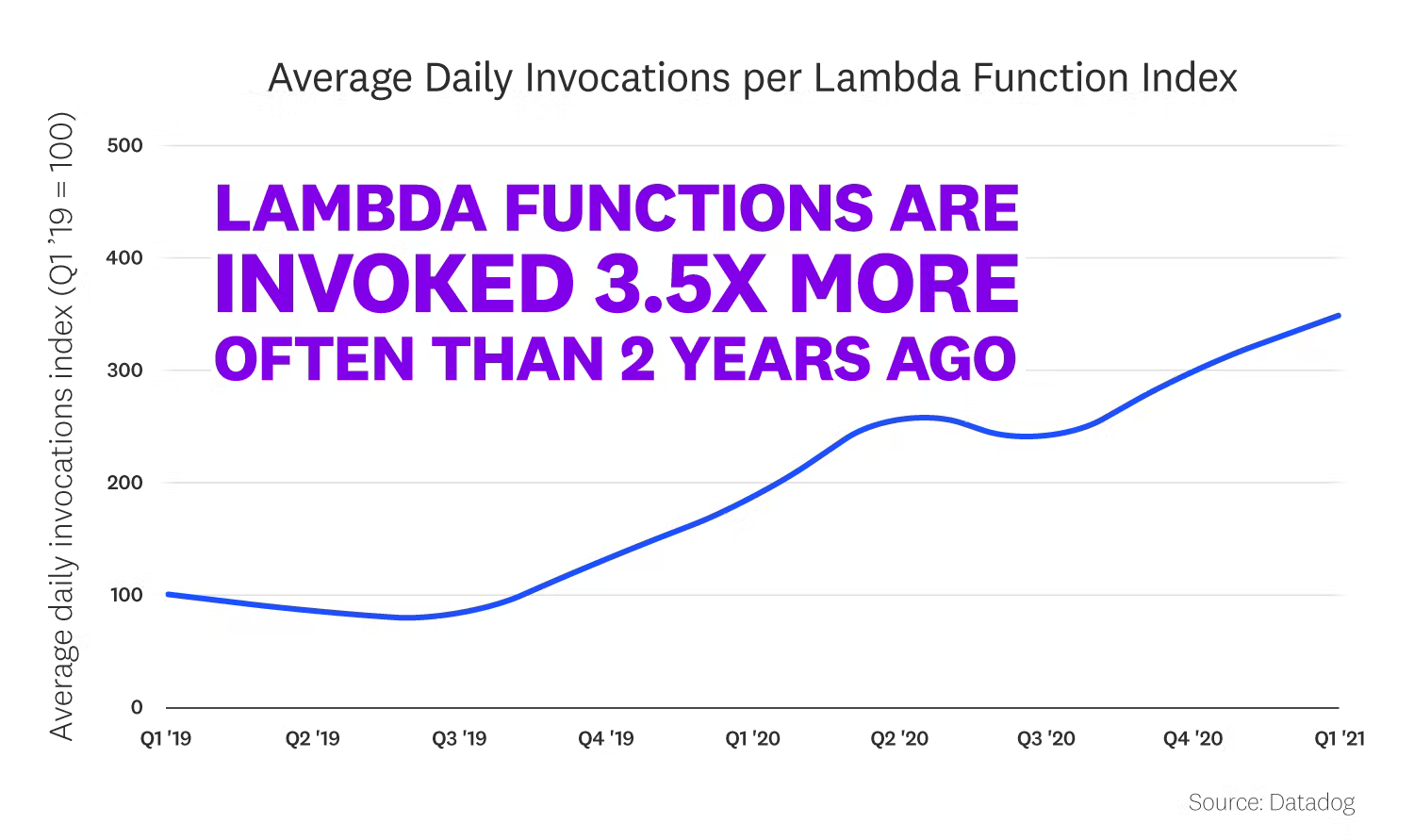
We don’t however naturally think of using serverless technology when it comes to ETL processes – for example moving raw sales data from an online retailer platform into a data warehouse. Traditionally these processes in many organisations are run on dedicated ETL platforms such as Apache Spark, Alteryx, and Informatica. These platforms are usually very powerful (and expensive!) as they are typically sized to cater for your worst-case workloads and are often “always on”.
Below is an example of a very common ETL requirement, taking some raw data from a CSV file, transform it into something more meaningful and load it into a cloud database (for example Google BigQuery).
In a serverless environment this can be done with a serverless function (for example, written in Python) deployed in the cloud that just sits there 24 hours a day, 7 days a week doing nothing, until a file appears in a particular object storage location.
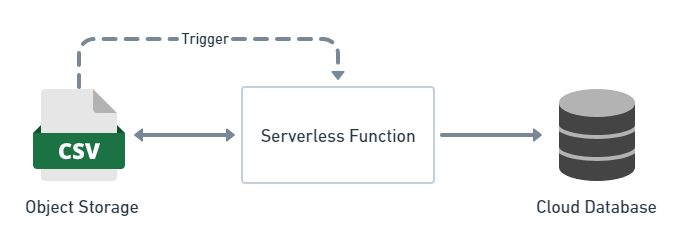
The moment the CSV file appears, the function is triggered where it then loads the data from the CSV file, transforms it (perhaps filters some data, re-shapes it, adds some calculated columns) and then finally inserts the transformed data into to a cloud database table.
The great thing about this architecture is that you don’t need to worry about any of the underlying cloud infrastructure used to utilise this. All the code has to know is where to get the data from, how to transform it and where to write it to. This is an example of a “Function as a Service” or FaaS.
As the output data from one function can become the input data for another function, you can very easily start to chain these processes together into ETL “pipelines”.
As they no longer have to think about infrastructure questions, your development teams can focus on solving business problems rather than dealing with infrastructure issues.
The nature of serverless actively forces you to adopt a micro services architecture so components and their dependencies are naturally isolated from each other. This makes them easier and faster to develop, test and deploy.
The example function above will run forever – it doesn’t need patching and is fully self contained – i.e. has no inter-dependency with any other processing function whatsoever. Even in the unlikely event that the database or storage goes down it will still stay deployed, and automatically start working again when those components come back up.
Depending on provider, there are few practical limits to the number of functions that can run simultaneously – cloud functions will scale up to whatever you need and down to zero instantly. So in our example above if a hundred files appear in the cloud storage location at once, a hundred cloud function instances will immediately spring into life to process them, all at the same time.
Serverless uses a “Pay As You Go” charging model, which means you only pay for what you use when you use it. In our example above while the function is sitting there idle it doesn’t cost a penny – you only get charged for the CPU seconds and memory used while it is actually processing the data.
Serverless functions can be deployed with different performance specifications (the better the spec, the more expensive those CPU seconds will be) and this gives you lots of flexibility with your costs. For example you can offload lower priority processing or I/O bound jobs where speed isn’t so important to lower spec (cheaper) functions, reserving your higher spec functions for the processes that really need it.
The pay as you go charging model can be extremely cost effective depending on your ETL workloads, particularly if they tend to be sporadic or “peaky” in nature. All cloud providers give you free CPU minutes every month and you may be surprised at just how much ETL you can do for nothing!
Serverless is by its very nature event driven. This makes it very easy to automate ETL processes that need to run when some kind of trigger “event” occurs. Functions can be automatically triggered by file events such as in the above example, but also by receiving an HTTPS request or Pub/Sub message or even when a transaction is written to a database.
Google Cloud, AWS and Azure all provide a variety of runtime environments for code, and those environments support a huge number of powerful libraries for manipulating data – Python, Java, Node, Go, .Net are examples. If your teams have the skills, you can mix and match your runtimes to suit your needs – a compiled Go serverless function may be more appropriate where speed is critical, this could happily integrate with a Python serverless function that returns results from a machine learning model all within the same overall data architecture.
And if your ETL processes require something rather more custom, cloud providers will also let you run your own containers within their serverless environments – with very similar scaling and charging models.
Runtimes are by their very nature open source, so you aren’t tied to any particular ETL software vendor, and in many circumstances your code can be written to be largely platform agnostic making it easier to switch cloud providers should you need to do so.
There are however some challenges to overcome when considering using serverless for your ETL processes. They aren’t suitable for all use cases.
In the same way a Pay As You Go mobile phone contract doesn’t make sense if you make hundreds of calls and download lots of data each month, serverless probably won’t make sense if your ETL workloads involve large scale bulk data transfers 24 hours a day, 7 days a week. An “always on” architecture in that scenario is likely to be more cost effective.
Serverless requires a different way of thinking about ETL. While simple ETL is very easy to do, things can get trickier very quickly when you need to construct more complex ETL processes that have multiple stages of processing with many inter-dependencies.
Why? Serverless functions by their very nature are designed to be ephemeral (instances of them appear and disappear very quickly) and they have no real knowledge of state (for example whether another function has finished processing) so you need to carefully consider how to handle this.
And lastly given the massive amount of potential concurrency available for processing, you have to think about the impact on your downstream systems and how to avoid possible bottlenecks. For example in our simple ETL scenario above where a hundred data files appear at the same time, you would need to make sure your target database could happily handle a hundred simultaneous bulk write operations.
It is not really possible to fully simulate your cloud environment locally and this does create challenges in testing your code before it gets deployed to the cloud. Debugging code while it is running in the cloud can also be difficult. Both issues can however be largely mitigated by ensuring you have sufficient test coverage in your CI/CD processes and careful logging enabled in each of your micro services.
Serverless functions have strict limits on how long they are allowed to run for and how much memory they can use. On AWS, for example, your function cannot run for more than 15 minutes or use more than 10GB of RAM. This means you have to be able to break up your data processing flow into small enough “chunks” so that each chunk a) fits into memory and b) can run within that time limit.
While this problem can often be overcome by simply splitting your data up so it can be processed by multiple functions in parallel (something you should try to do anyway for performance reasons), it may not always be possible.
Cloud providers are gradually extending these limits however and we expect this will become less of an issue over time. Google recently launched their second generation Cloud Function platform, for example, and the table below shows how their limits have increased – indicative of how much potential they see in using serverless technology for longer running processing such as ETL.
| AWS Lambda | Azure Functions (Consumption Plan)* | Google Cloud Functions (Gen 1) | Google Cloud Functions (Gen 2)** | |
| Memory (GB) | 10 | 1.5 | 8 | 16 |
| Execution Time (Minutes) | 15 | 10 | 10 | 60 |
* There are Azure Function plans with higher maximum execution times and memory limits but they have a very different charging model requiring upfront commitment – i.e. are not “pay as you go”.
** Currently in public preview.
Serverless technologies have matured significantly in the last few years and while their adoption in organisations has mostly been confined to “short lived” transactional processes, we believe there is now a strong case to use them for ETL purposes.
They offer many opportunities for organisations to simplify and reduce latency in their data architectures, lower their ongoing development, maintenance and operations costs and speed up the delivery of data projects.


